정보처리기사 오답노트
- = : 자료의 정의
- + : 자료의 연결
- ( ) : 자료의 생략
- [ ] : 자료의 선택
- { } : 자료의 반복
- ** : 자료의 설명
집단화는 객체지향 프로그래밍에서 클래스들 사이의 '부분-전체' 관계를 나타내는 용어입니다. 즉, 한 클래스가 다른 클래스의 일부분이 되는 것을 의미합니다. 예를 들어, 자동차 클래스는 엔진, 바퀴, 핸들 등의 부품 클래스들의 집단화된 형태로 구성될 수 있습니다.
일반화는 상속 관계를 나타내는 용어이며, 추상화는 객체의 공통적인 특성을 추출하여 클래스로 정의하는 과정을 의미합니다. 캡슐화는 객체의 속성과 행위를 하나로 묶어 정보 은닉을 위한 기법입니다.

- xUnit : 다양한 언어 지원
- STAF : 컴포넌트 재사용
- FitNesse : 웹 기반
- NTAF : STAF + FitNesse
- Selenium : 다양한 브라우저 지원
- watir : Ruby 언어 사용
SMTP는 이메일 전송 프로토콜로, 인터페이스 보안을 위한 네트워크 영역에 적용될 수 있는 솔루션과는 거리가 먼 것입니다. SMTP는 이메일을 전송하는 데 사용되는 프로토콜이며, 이메일 보안을 위한 다른 프로토콜과는 별개로 동작합니다. 반면, IPSec, SSL, S-HTTP 등은 네트워크 통신을 암호화하고 보안을 강화하는 프로토콜로, 인터페이스 보안을 위해 적용될 수 있는 솔루션으로 자주 사용됩니다.
- LOC : 원시코드 라인수의 비관치, 낙관치, 기대치 측정
- COCOMO : LOC에 의한 비용 산정 기법
- Putnam : Rayleigh-Norden 곡선의 노력 분포도를 기초로 비용 산출
- 기능점수 : 가중치 부여
※ 델파이 : 전문가 감정 기법의 주관적인 편견을 보완하는 하향식 기법
- 클래스 다이어그램
- 객체 다이어그램
- 컴포넌트 다이어그램
- 배치 다이어그램
- 복합체 다이어그램
- 패키지 다이어그램
행위적(동적) 다이어그램
- 유스케이스 다이어그램
- 시퀀스 다이어그램
- 커뮤니케이션 다이어그램
- 상태 다이어그램
- 활동 다이어그램
- 상호 작용 개요 다이어그램
- 타이밍 다이어그램
- SRP(단일 책임 원칙) : 하나의 클래스는 하나의 책임만 가져야 한다.
- OCP(개방-폐쇄 원칙) : 소프트웨어 요소는 확장에는 열려 있으나 변경에는 닫혀 있어야 한다.
- LSP(리스코프 치환 원칙) : 하(상)위 타입 객체는 상(하)위 타입 객체에서 가능한 행위를 수행할 수 있어야 한다.
- ISP(인터페이스 분리 원칙) : 클라이언트는 자신이 사용하는 메소드에만 의존해야 한다.
- DIP(의존 역전 원칙) : 의존 관계를 맺을 때, 변하기 쉬운 구체적인 것 보다는 변하기 어려운 추상적인 것에 의존해야 한다. 즉, 구현 클래스에 의존하지 말고, 인터페이스에 의존하라는 뜻이다.
LSP는 상위 클래스와 하위 클래스 간의 교체 가능성을 보장하여 다형성을 지원하고, 이를 통해 유연하고 확장 가능한 코드를 작성할 수 있도록 돕는 객체지향 설계 원칙입니다. 즉, 하위 클래스는 상위 클래스의 모든 기능을 사용할 수 있어야 하며, 상위 클래스에서 정의한 규약을 준수해야 합니다. 이를 통해 코드의 일관성과 안정성을 유지할 수 있습니다. ISP는 인터페이스를 작은 단위로 분리하여 의존성을 낮추는 원칙, DIP는 추상화를 통해 의존성을 역전시키는 원칙, SRP는 클래스나 모듈은 하나의 책임만 가져야 한다는 원칙입니다.
- 레인지 파티셔닝(범위분할)
- 해시 파티셔닝(해시분할)
- 리스트 파티셔닝
- 컴포지트 파티셔닝(조합분할)
유닛분할(Unit Partitioning)은 파티션을 일정한 크기의 블록으로 분할하는 것으로, 데이터의 특성에 따라 유연하게 조절할 수 없어서 파티션 설계에서 사용되지 않는 유형입니다. 범위분할(Range Partitioning), 해시분할(Hash Partitioning), 조합분할(Composite Partitioning)은 데이터의 특성에 따라 파티션을 유연하게 조절할 수 있어서 파티션 설계에서 사용됩니다.
- 위치 투명성(Location Transparency)
- 중복 투명성(Replication Transparency)
- 분할 투명성(Division Transparency)
- 병행 투명성(Concurrency Transparency)
- 장애 투명성(Failure Transparency)
분산 데이터베이스에서의 투명성은 사용자나 응용 프로그램이 분산 데이터베이스를 사용할 때 분산 시스템의 내부 동작을 알 필요 없이 일관된 인터페이스를 제공하는 것을 말합니다. 따라서 "Media Access Transparency"는 분산 데이터베이스의 투명성에 해당하지 않습니다. 이는 데이터가 저장된 미디어(하드디스크, SSD 등)에 대한 접근 방법에 대한 투명성을 의미하는데, 이는 분산 데이터베이스의 구성과는 직접적인 연관성이 없기 때문입니다.
- 지연 갱신 기법 → REDO
- 즉각 갱신 기법 → UNDO
즉각 갱신 기법은 데이터를 변경할 때마다 로그를 즉시 기록하여 데이터베이스의 일관성을 유지하는 회복 기법이다. 다른 세 가지 기법은 모두 데이터 변경 시 로그를 기록하지만, 즉각 갱신 기법과는 달리 로그를 기록하는 시점이 다르다. 따라서 즉각 갱신 기법은 데이터베이스의 신뢰성을 높이는 데 효과적이다.
- Select(σ)
- Project(π)
- Join(▷◁)
- Division(÷)
일반집합 연산자 #합교차카
- Union(합집합)
- Intersection(교집합)
- Difference(차집합)
- Cartesian Product(교차곱)
- 대용량 데이터
- 자동화
- 견고성
- 안정성/신뢰성
- 성능
주어진 시간에 작업을 완료해야 하고, 다른 애플리케이션의 동작을 방해하지 않아야 한다는 것은 '성능'이라는 요소에 대한 설명입니다.
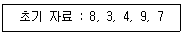
- 기초 경로 검사
- 조건 검사
- 루프 검사
- 데이터 흐름 검사
- 동치 분할 검사
- 경계값 분석
- 원인-효과 그래프 검사
- 비교 검사
- 오류 예측 검사
기초 경로 검사는 프로그램의 모든 가능한 경로를 식별하고 각 경로를 한 번 이상 실행하여 프로그램의 오류를 찾는 데 사용되는 테스트 기법입니다. 따라서 다른 세 가지 옵션인 동치 클래스 분해, 경계값 분석, 원인 결과 그래프는 특정 입력 값에 대한 테스트를 중점적으로 수행하는 데 비해, 기초 경로 검사는 프로그램의 전반적인 동작을 테스트하는 데 초점을 맞추고 있습니다. 이러한 이유로 기초 경로 검사는 블랙박스 테스트 기법 중에서 거리가 먼 것으로 선택됩니다.
- 제산법 : 가장 작은 소수로 나눈 나머지
- 폴딩법 : 여러 부분으로 나눈 후 더하거나 XOR
- 기수변환법 : 다른 진수로 변환시키고 초과한 자릿수 자름
- 숫자분석법 : 비교적 고른 자리를 필요한 만큼 선택
해싱함수 중 레코드 키를 여러 부분으로 나누고, 나눈 부분의 각 숫자를 더하거나 XOR한 값을 홈 주소로 사용하는 방식은 폴딩법이다. 이는 레코드 키를 여러 부분으로 나누어 각 부분을 더하거나 XOR하여 홈 주소를 생성하기 때문에, 레코드 키의 일부분만을 이용하여 해시값을 생성할 수 있어서 효율적이다. 또한, 레코드 키의 길이가 다른 경우에도 적용할 수 있어서 유용하다.
- 논리적 데이터 구조
- 연산
- 제약 조건
다른 요소들은 데이터 모델의 구성 요소로서 데이터의 구조와 관계를 표현하는 것이지만, 출력 구조는 데이터 모델의 외부에서 데이터를 표시하는 방법에 대한 것이므로 데이터 모델에 표시할 필요가 없다. 따라서 출력 구조가 데이터 모델에 표시해야 할 요소로서는 거리가 먼 것이다.
- 내용 결합도(Content Coupling) : 한 모듈이 다른 모듈의 내부 기능 및 그 내부 자료를 직접 참조하거나 수정(public 속성)할 때의 결합도
- 공유 결합도(Common Coupling) : 공유되는 공통 데이터 영역(전역변수)을 여러 모듈이 사용할 때의 결합도
- 외부 결합도(External Coupling) : 어떤 모듈에서 선언한 데이터(변수)를 외부의 다른 모듈에서 참조할 때의 결합도
- 제어 결합도(Control Coupling) : 어떤 모듈이 다른 모듈 내부의 논리적인 흐름을 제어하기 위해 제어 신로를 통신하거나 제어 요소(Flag)를 전달하는 결합도
- 스탬프 결합도(Stamp Coupling) : 모듈 간의 인터페이스로 배열이나 레코드 등의 자료 구조가 전달될 때의 결합도
- 자료 결합도(Data Couplign) : 모듈 간의 인터페이스가 자료 요소로만 구성될 때의 결합도
- 우연적 응집도(Coincidental Cohesion) : 모듈 내부의 각 구성 요소들이 서로 관련 없는 요소로만 구성된 경우의 응집도
- 논리적 응집도(Logical Cohesion) : 유사한 성격을 갖거나 특정 형태로 분류되는 처리 요소들로 하나의 모듈이 형성되는 경우의 응집도
- 시간적 응집도(Temporal Cohesion) : 특정 시간에 처리되는 몇 개의 기능을 모아 하느이 모듈로 작성할 경우의 응집도
- 절차적 응집도(Procedural Cohesion) : 모듈의 다수의 관련 기능을 가질 때 모듈 안의 구성 요소들이 그 기능을 순차적으로 수행할 경우의 응집도
- 교환적 응집도(Communication Cohesion) : 동일한 입력과 출력을 사용해 서로 다른 기능을 수행하는 구성 요소들이 모였을 경우의 응집도
- 순차적 응집도(Sequential Cohesion) : 모듈 내 하나의 활동으로부터 나온 출력 데이터를 그 다음 활동의 입력 데이터로 사용할 경우의 응집도
- 기능적 응집도(Functional Cohesion) : 모듈 내부의 모든 기능 요소들이 단일 문제와 연관되어 수행될 경우의 응집도
- 초기 단계(initial)
- 반복 단계(repeatable)
- 정의 단계(defined)
- 관리 단계(managed)
- 최적 단계(optimizing)
- 표현
- 프로세스
- 서비스
- 비즈니스
- 영속
제어 클래스층은 서비스 지향 아키텍처에서 사용되지 않는다. 대신, 서비스 지향 아키텍처에서는 표현층, 프로세스층, 비즈니스층으로 구성된다. 제어 클래스층은 일반적으로 모델-뷰-컨트롤러(MVC) 아키텍처에서 사용된다.
- SREM : TRW에서 개발, RSL과 REVS 사용
- PSL/PSA : 미시간 대학에서 개발
- HIPO : 시스템의 분석 및 설계나 문서화에 사용
- SADT : SoftTech에서 개발, 블록 다이어그램 채택
- TAGS : 개발 주기의 전 과정에 사용 가능
SADT는 구조적 분석 기법 중 하나로, 블록 다이어그램을 사용하여 시스템의 구조와 기능을 분석하는 방법이다. 따라서 구조적 요구 분석을 위해 블록 다이어그램을 채택한 자동화 도구는 SADT이다.
- 논리의 기술에 중점을 둔 도형식 표현 방법
- 전문성이 있어야 그리기 쉬움 (그리기 어려움)
- 연속, 선택 및 다중 선택, 반복 등의 제어논리 구조로 표현함
- 임의의 제어 이동이 어려움 → goto구조가 어려움
- 그래픽 설계 도구임
- 상자 도표라고도 함
- 프로그램으로 구현이 쉬움
- 조건이 복합되어 있는 곳의 처리를 시각적으로 명확히 식별하는데 적합함
- 연관 관계 : 액터와 유스케이스 간 상호작용이 존재?
- 포함 관계 : 유스케이스 실행을 위해 반드시 실행되어야 하는 유스케이스가 존재?
- 확장 관계 : 유스케이스를 실행함으로써 선택적으로 실행되는 유스케이스가 존재?
- 일반화 관계 : 액터 또는 유스케이스가 구체화된 다른 액터 또는 유스케이스를 가지는가?
기본 유스케이스 수행 시 특별한 조건을 만족할 때 수행하는 유스케이스는 "확장"이다. 이는 기본 유스케이스에서 예외 상황이 발생했을 때 대처하기 위한 유스케이스로, 기본 유스케이스와는 별도로 정의되며, 선택적으로 수행된다. 따라서 "확장"은 기본 유스케이스의 보완적인 역할을 수행하며, 예외 상황에 대한 처리를 보다 체계적으로 할 수 있도록 도와준다.
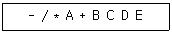
정답은 "A B C + * D / E -" 이다.
전위식에서는 연산자가 피연산자보다 먼저 나오고, 후위식에서는 연산자가 피연산자보다 나중에 나온다. 따라서 전위식을 후위식으로 바꾸기 위해서는 다음과 같은 과정을 거친다.
- 전위식에서 가장 오른쪽에 있는 피연산자인 "E"를 후위식으로 옮긴다.
- 다음으로 오른쪽에 있는 연산자인 "-"를 후위식으로 옮긴다.
- "-" 다음에 오는 피연산자인 "D"를 후위식으로 옮긴다.
- "/" 연산자를 후위식으로 옮긴다.
- "/" 다음에 오는 피연산자인 "C"와 "D"를 후위식으로 옮긴다.
- "+" 연산자를 후위식으로 옮긴다.
- "+" 다음에 오는 피연산자인 "A"와 "B"를 후위식으로 옮긴다.
- "*" 연산자를 후위식으로 옮긴다.
- "*" 다음에 오는 피연산자인 "A", "B", "C"를 후위식으로 옮긴다.
따라서 "A B C + * D / E -"가 옳은 후위식이다.
- Correctness(정확성) : 사용자의 요구기능을 충족시키는 정도
- Reliability(신뢰성) : 요구된 기능을 오류없이 수행하는 정도
- Efficiency(효율성) : 요구된 기능을 수행하기 위한 시스템능력과 필요한 자원의 소요정도
- Portability(이식성) : 다양한 하드웨어 환경에서도 운용 가능하도록 쉽게 수정할 수 있는 정도
- Integrity(무결성) : 허용되지 않는 사용이나 자료의 변경을 제어하는 정도
- Usability(유용성) : 쉽게 사용할 수 있는 정도
- Flexibility(유연성) : 새로운 요구사항에 맞게 얼마만큼 쉽게 수정할 수 있는지의 정도
- Reusability(재사용성) : 이미 만들어진 프로그램을 다른 목적으로 사용할 수 있는지의 정도
- Interoperability(상호운용성) : 다른 소프트웨어와 정보를 교환할 수 있는 정도
Usability는 사용자가 쉽게 배우고 사용할 수 있는 정도를 나타내는 목표이기 때문입니다. 다른 목표들은 소프트웨어의 기능적인 측면을 중심으로 한 것이지만, Usability는 사용자의 경험과 만족도를 고려한 목표입니다. 따라서 소프트웨어를 개발할 때, 사용자의 편의성과 직관성을 고려하여 설계하고 구현해야 합니다.
정답은 "레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬한다."이다.
퀵 정렬은 분할 정복 알고리즘의 하나로, 주어진 배열을 두 개의 부분 배열로 분할하고 각 부분 배열을 재귀적으로 정렬하는 방식으로 동작한다. 이 때, 퀵 정렬은 pivot 값을 기준으로 작은 값은 왼쪽으로, 큰 값은 오른쪽으로 분할하며, 이 과정에서 레코드의 이동이 발생한다.
하지만, 퀵 정렬은 pivot 값을 잘 선택하지 못하면 최악의 경우 O(n^2)의 시간 복잡도를 가지게 된다. 따라서, 퀵 정렬에서는 pivot 값을 잘 선택하는 것이 중요하며, 이를 위해 다양한 방법들이 제안되고 있다.
또한, 퀵 정렬은 대부분의 경우에 다른 정렬 알고리즘보다 빠르게 동작하며, 특히 대용량 데이터를 정렬할 때 유용하다.
- 제산법 : 가장 작은 소수로 나눈 나머지
- 폴딩법 : 여러 부분으로 나눈 후 더하거나 XOR
- 기수변환법 : 다른 진수로 변환시키고 초과한 자릿수 자름
- 숫자분석법 : 비교적 고른 자리를 필요한 만큼 선택
개방주소법은 해시 충돌이 발생했을 때 다른 빈 공간을 찾아 해시 테이블 내부에서 충돌을 해결하는 방법이다. 따라서 해싱 함수의 종류가 아니라 충돌 해결 방법이다. 따라서 정답은 "개방주소법(open addressing)"이다.

- MQTT : 메시지 브로커를 통해 송신자가 특정 메시지를 발행하고 수신자가 메시지를 구독하는 방식의 경량 메시지 전송 프로토콜
- TELNET : 최초의 인터넷 연결 네트워크 프로토콜
- GPN : 특정 제춤이나 서비스가 생산, 유통 및 소비되는 상호 연결된 기능, 운영 및 거래의 연계
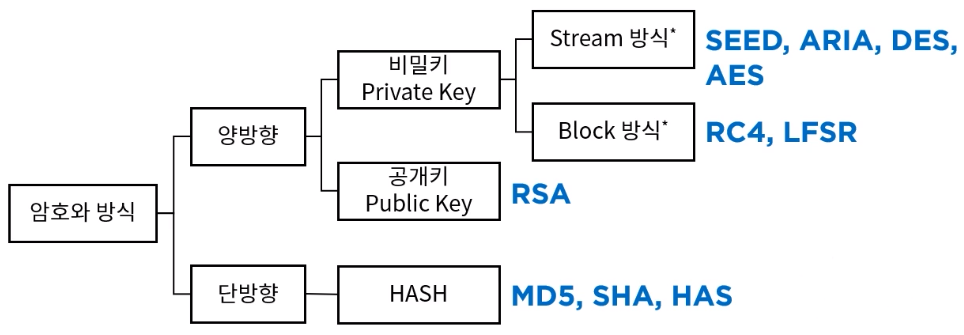
- 양방향
- 비밀키
- 블록 SEED ARIA DES AES
- 스트림 RC4 LFSR
- 공개키 RSA
- 비밀키
- 단반향
- 해시 MD5 SHA HAS
해쉬 함수는 메시지 무결성을 검증하기 위한 용도로 사용되며, 스트림 암호화 방식과는 직접적인 연관성이 없습니다. 따라서 "해쉬 함수를 이용한 해쉬 암호화 방식을 사용한다."는 스트림 암호화 방식의 설명으로 옳지 않습니다.
- 가용성
- 변경 용이성
- 성능
- 보안성
- 사용 편의성
- 시험 용이성
시스템 품질속성 중 독립성은 아키텍처 설계에서 고려되는 속성이 아닙니다. 독립성은 일반적으로 모듈화와 관련이 있으며, 모듈 간의 상호작용을 최소화하여 모듈의 독립성을 높이는 것을 의미합니다. 따라서 시스템 품질속성으로는 고려되지 않습니다.
- CASE 분류
- 상위 CASE : 모델들 사이의 모순 검사, 모델의 오류 검증, 자료 흐름도 작성 등 지원
- 하위 CASE : 코드의 작성과 테스트, 문서화하는 과정 지원
- 통합(Integrate) CASE : 소프트웨어 생명 주기 전체 과정 지원
- CASE 원천 기술
- 구조적 기법
- 프로토타이핑 기술
- 자동 프로그래밍 기술
- 정보 저장소 기술
- 분산처리 기술
- CASE 도구의 기능 및 효과
- 소프트웨어 생명 주기 전 단계의 연결
- 다양한 소프트웨어 개발 모형 지원
- 소프트웨어 모듈의 재사용성 향상
- 소프트웨어 품질 향상
- 소프트웨어 유지보수 간편하게 수행 가능
- 요구사항 분석 CASE 종류
- SADT : SoftTech사에서 개발된 것으로, 구조적 요구 분석을 하기 위해 블록 다이어그램을 채택한 자동화 도구
- SREM : TRW가 우주 국방 시스템 그룹에 의해 실시간 처리 소프트웨어 시스템에서 요구사항을 명확히 기술할 목적으로 개발한 도구
- PSL/PSA : 미시간 대학에서 개발한 것으로 PSL과 PSA를 사용하는 도구
- TAGS : 시스템 공학 방법 응용에 대한 자동 접근 방법으로, 개발 주기의 전 과정에서 이용할 수 있는 통합 도구
[출처] [정보처리기사 필기] 1과목.소프트웨어 설계 핵심 요약 - 요구사항 분석 및 설계 도구|작성자 기사퍼스트
일괄처리 기술은 CASE의 원천 기술이 아닙니다. CASE는 소프트웨어 개발 과정에서 자동화된 도구와 기법을 사용하여 생산성을 높이고 품질을 향상시키는 방법론입니다. 일괄처리 기술은 데이터 처리를 위한 방법으로, CASE와는 관련이 없습니다.
- 구조적(정적) 다이어그램
- 클래스 다이어그램
- 객체 다이어그램
- 컴포넌트 다이어그램
- 배치 다이어그램
- 복합체 다이어그램
- 패키지 다이어그램
- 행위적(동적) 다이어그램
- 유스케이스 다이어그램
- 시퀀스 다이어그램
- 커뮤니케이션 다이어그램
- 상태 다이어그램
- 활동 다이어그램
- 상호 작용 개요 다이어그램
- 타이밍 다이어그램
절차 다이어그램은 UML의 공식 다이어그램이 아니며, 프로세스 흐름을 나타내는 다이어그램으로 사용됩니다. 따라서 정답은 "절차 다이어그램(Procedural diagram)"입니다.
- Dependency : 한 사물의 명세서가 바뀌면 그것을 사용하는 다른 사물에게 영향을 끼치는 것
- Realization : 한 객체가 다른 객체가 오퍼레이션을 수행하도록 지정하는 의미적 관계
- Generalization : 일반화된 사물과 더 특수화된 사물 사이의 관계
- Association : 어느 객체가 다른 객체와 연결되어 있다는 구조적 관계
"Realization"은 인터페이스를 구현하는 클래스와 같이, 한 객체가 다른 객체에게 오퍼레이션을 수행하도록 지정하는 의미적 관계입니다. 이 관계는 인터페이스와 구현체 사이의 관계를 나타내며, 인터페이스에서 정의된 메서드를 구현체에서 실제로 구현하여 사용할 수 있도록 합니다. 따라서 "Realization"이 정답입니다.
- 클리어링 하우스(Clearing House): 저작권에 대한 사용 권한, 라이선스 발급, 사용량에 따른 관리 등을 수행하는 곳
- 콘텐츠 제공자(Contents Provider): 콘텐츠를 제공하는 저작권자
- 패키저(Packager): 콘텐츠를 메타 데이터(데이터의 속성 정보를 설명하는 데이터)와 함께 배포 가능한 형태로 묶어 암호화하는 프로그램
- 콘텐츠 분배자(Contents Distributor): 암호화된 콘텐츠를 유통하는 곳이나 사람
- 콘텐츠 소비자(Customer): 콘텐츠를 구매해서 사용하는 주체
- DRM 컨트롤러(DRM Controller): 배포된 콘텐츠의 이용 권한을 통제하는 프로그램
- 보안 컨테이너(Security Container): 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치
"Dataware house"는 데이터 저장 및 관리를 위한 시스템으로, 디지털 저작권 관리(DRM)와 직접적인 연관성이 없습니다. 따라서, "Dataware house"가 디지털 저작권 관리(DRM) 구성 요소가 아닙니다.
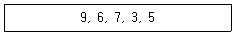
첫번째로 초기값 9,6,7,3,5 에서 9,6 부분을 먼저 보도록 하겠습니다! 두 부분을 봤을 때 더 작은 수가 앞으로 옮겨 가면 됩니다! 9와 6중 6이 더 작은 숫자이기때문에 6,9로 변경이 가능합니다.
다음으로 두 번째로 9,7을 확인 해주면 됩니다 7이 더 작은 숫자 이므로 7,9가 되겠네요. 이제 첫번째와 두번째를 합치게 되면 6,7,9가 되겠네요!!
다음으로 세 번째로 9,3 부분을 확인 해보겠습니다 3이 더 작은 숫자이니 3,9가 되겠네요. 1,2,3번째를 합치게 되면 6,7,3,9 가 되겠네요!!
계속해서 비교를 해보면 이제 9,5를 비교하면 되겠습니다! 그럼 이제 5,9로 변환이 가능하겠죠?
1,2,3,4번째를 합치게 되면 6,7,3,5,9로 정리가 될 수 있겠네요! 여기까지가 Pass1 단계입니다!
Pass1단계에서 나온 값을 한번더 동일한 방식으로 하게 되면 Pass2 단계가 됩니다. Pass1 단계에서 나온 값인 6,7,3,5,9에서 6,7를 비교 하게 되면 6이 작은 숫자이므로 옮겨주면 되겠지만 이미 옮겨져있기에 그냥 넘어 갑니다.
두 번째로 7,3을 비교 하면 3이 작으니 3,7이 되겠네요. 첫번째와 합치게 되면 6,3,7이 되겠네요 .
다음으로 7,5를 비교 하면 5가 작으니 5,7이 되고, 합치게 되면 6,3,5,7 이 되네요 마지막으로 7,9를 비교 하면 7이 작으니 그대로 가면 되겠습니다.
결론적으로 Pass2 단계의 결과 값은 6,3,5,7,9가 되겠네요!!
[출처] 버블 정렬(Bubble sort) 공부하기!!|작성자 IT 공대생

- STA: STA는 Station의 약자로, 무선 네트워크에 연결된 장치를 의미합니다.
- Collision Domain: Collision Domain은 충돌 도메인으로, 같은 네트워크 상에서 충돌이 발생할 수 있는 영역을 의미합니다.
- CSMA/CA: CSMA/CA는 Carrier Sense Multiple Access with Collision Avoidance의 약자로, 무선 네트워크에서 충돌을 방지하기 위한 방식입니다. 이 방식은 데이터를 전송하기 전에 채널을 감지하여 사용 중인지 여부를 확인하고, 사용 중이 아니면 데이터를 전송합니다. 그러나 무선 환경에서는 채널이 사용 중이더라도 신호가 약하거나 간섭이 발생할 수 있으므로, 충돌을 방지하기 위해 데이터를 전송하기 전에 무작위로 대기하는 시간을 둡니다. 이를 Backoff time이라고 합니다.
- CSMA/CD: CSMA/CD는 Carrier Sense Multiple Access with Collision Detection의 약자로, 유선 네트워크에서 충돌을 방지하기 위한 방식입니다. 그러나 무선 환경에서는 CSMA/CD 방식을 사용할 수 없습니다.
- CSMA/CD : 유선 LAN(이더넷)
- CSMA/CA : 무선 LAN
203.241.132.82/27
→ 2^(32-CIDR개수) = 2^(32-27) = 2^5
→ 네트워크 호스트 자리 5자리가 0임
→ 1110 0000
→ 128 + 64 + 32 = 224
CIDR 표기에서 /27은 27비트가 네트워크 부분에 할당되고 나머지 5비트가 호스트 부분에 할당된다는 것을 의미합니다. 따라서 서브넷 마스크는 네트워크 부분이 모두 1이고 호스트 부분이 모두 0인 32비트 마스크를 사용해야 합니다. 이를 8비트씩 나누어 표기하면 255.255.255.224가 됩니다. 따라서 정답은 "255.255.255.224"입니다.
- 기억 장소 이용 효율 ↑
- 입출력 시간 ↑
- 페이지 맵 테이블 크기 ↑
- 내부 단편화 ↓
페이지 맵 테이블은 가상 주소와 물리 주소 간의 매핑 정보를 담고 있는 테이블입니다. 페이지 크기가 작아질수록 페이지 수가 증가하게 되고, 이에 따라 페이지 맵 테이블에 저장되는 매핑 정보의 수도 증가합니다. 따라서 페이지 크기가 작아질수록 페이지 맵 테이블의 크기는 증가하게 됩니다.
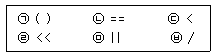
- 괄호, 배열, 구조체 () [] . →
- 단항 연산 - ! ~ ++ (type) & * sizeof()
- 산술 연산
- 승제 * / %
- 가감 + -
- 비트 이동 연산 >> <<
- 관계 연산
- 비교 < <= > >=
- 등가 == !=
- 비트 논리 연산 & | ^
- 논리 연산 && ||
- 조건 연산 ? :
- 대입 연산
- 대입 =
- 축약형대입 += -= *= /= %=
- 축약형비트대입 >>= <<=

- SAN(Stroage Area Network) : 서버와 저장장치를 연결하는 전용 네트워크를 별도로 구성하는 방식
- DAS(Direct Attached Storage) : 서버와 저장장치를 전용 케이블로 직접 연결하는 방식
- NAS(Network Attached Storage) : 서버와 저장장치를 네트워크를 통해 연결하는 방식
※ MBR : HDD의 첫번째 섹터에 저장되는 부트로더 정보
※ NIC : 컴퓨터와 네트워크를 연결하기 위한 HW 장치
※ NAC : 네트워크에 접속하는 장치의 인증 및 접근 권한 제어
SAN (Storage Area Network)은 여러 대의 서버, 호스트 및 스토리지 장치가 네트워크를 통해 서로 통신하는 것을 말합니다. SAN은 여러 대의 컴퓨터 및 서버에서 공유할 수 있는 공유 스토리지 풀을 제공하기 위해 사용됩니다. SAN은 대개 광케이블을 사용하여 데이터를 전송하며, 높은 대역폭과 낮은 지연 시간을 제공합니다. SAN은 대규모 데이터 센터 및 기업에서 많이 사용되며, 대용량 데이터의 저장 및 관리를 위해 사용됩니다.

- Bell-Lapadula Model : 권한 레벨이 같거나 낮은 등급만 읽을 수 있고, 권한 레벨이 같거나 높은 등급만 쓸 수 있다.
- Biba Integrity Model : 무결성을 위한 변조 방지
- Clark-Wilson Integrity Model : 사용자가 직접 객체에 접근할 수 없고, 프로그램을 통해서만 접근 가능하다.
- Chinese Wall Model : 사용자의 이전 동작에 따라 변화할 수 있는 접근 통제 제공
※ PDCA : Plan-Do-Check-Act
이 모델은 Bell-Lapadula Model이다. 이 모델은 기밀성을 중요시하는 모델로, 정보의 노출을 방지하기 위해 객체와 주체에 대한 접근 권한을 제한하는 모델이다. 이 모델은 정보의 비밀성을 유지하기 위해 "no read up"과 "no write down" 규칙을 적용한다. 즉, 보안 수준이 높은 객체에서 낮은 객체로의 읽기는 허용하지 않으며, 보안 수준이 낮은 객체에서 높은 객체로의 쓰기는 허용하지 않는다.
- 불완전
- 수행
- 관리
- 확립
- 예측
- 최적화
Dependency는 한 클래스가 다른 클래스를 사용하는 관계를 나타내며, 한 사물의 명세가 바뀌면 다른 사물에 영향을 주는 경우가 있습니다. 이 관계는 일반적으로 한 클래스가 다른 클래스를 오퍼레이션의 매개변수로 사용하는 경우에 나타납니다.
Association은 두 클래스 간의 관계를 나타내며, 두 클래스가 서로를 참조하는 경우에 사용됩니다.
Realization은 인터페이스와 구현 클래스 간의 관계를 나타내며, 인터페이스를 구현하는 클래스가 있을 때 사용됩니다.
Generalization은 상속 관계를 나타내며, 부모 클래스와 자식 클래스 간의 관계를 나타냅니다.
- 검증 : 개발 단계의 제품이 단계의 시작 부분에서 부과된 조건을 만족시키는지 평가
- 확인 : 소프트웨어가 특정 요구 조건을 만족시키는지 개발 과정 중이나 후에 평가
검증은 개발자중심 시스템 검정 과정, 과정을 중시한다고 생각하면 되고, 확인은 사용자 중심 시스템 검정과정, 결과를 잘 충족했는지를 중시한다고 생각하면 됨.
- 이진 탐색 트리 : O(n)
- AVL 트리 : O(log n)
- 2-3 트리 : O(log3n)
- 레드-블랙 트리 : O(log n)
이진 탐색트리는 데이터가 정렬되어 있지 않은 경우, 최악의 경우에는 모든 노드를 탐색해야 하기 때문에 검색 효율이 가장 나쁩니다. 이는 트리의 높이가 데이터의 개수와 같아지는 경우에 발생합니다. 따라서 이진 탐색트리는 데이터가 정렬되어 있을 때 가장 효율적으로 작동하며, 데이터의 삽입, 삭제에 대한 처리도 다른 트리 구조에 비해 복잡합니다.
- 자동반복 요청방식(ARQ: Automatic Repeat reQuest)
- Stop-and-Wait ARQ(정지-대기 ARQ): 송신 측이 하나의 블록을 전송한 후 수신 측에서 에러의 발생을 점검한 다음, 에러 발생 유무 신호를 보내올 때까지 기다리는 방식
- Go-Back-N ARQ: 여러 블록을 연속적으로 전송하고, 수신 측에서 부정 응답(NAK)을 보내오면 송신 측이 오류가 발생한 블록부터 모두 재 전송
- Selective-Repeat ARQ(선택적 재전송 ARQ): 여러 블록을 연속적으로 전송하고, 수신측에서 부정 응답(NAK)을 보내오면 송신 측이 오류가 발생한 블록만을 재전송
- Adaptive ARQ(적응적 ARQ): 전송 효율을 최대로 하기 위 해서 데이터 블록의 길이를 채널의 상태에 따라 동적으로 변 경하는 방식
Non-Acknowledge ARQ는 수신 측에서 패킷을 받았음에도 불구하고 응답을 보내지 않는 방식으로 오류 제어를 수행합니다. 따라서 이 방식은 자동반복 요청방식(ARQ)이 아닙니다. Stop-and-wait ARQ, Go-back-N ARQ, Selective-Repeat ARQ은 모두 자동반복 요청방식(ARQ)입니다.
- 강제 접근 통제(Mandatory Access Control) : 주체와 객체의 등 급을 비교하여 접근 권한을 부여하는 방식 임의접근통제(Discretionary Access Control), 접근하는 사용 자의 신원에 따라 접근 권한을 부여하는 방식
- 사용자 계정 컨트롤(User Access Control) : 프로그램에서 관리 자 수준의 권한이 필요한 작업을 수행할 때 사용자에게 알려 서 제어할 수 있도록 돕는 기능
- 자료별 접근통제(Data-Label Access Control >Label-Based Access Control) : 개별 행, 열에 대해 쓰기 권한, 읽기 권한을 가졌는지를 명확하게 결정하는 제어 방식
- MQTT : IBM에서 개발한 발행/구독 프로토콜로, TCP/IP를 통해 실행되어 기본 네트워크 연결을 제공함.
- MLFQ(Multi Level Feedback Queue) : 짧은 작업 이나 입출력 위주의 프로세스에 우선순위를 부여하는 선점형 스케줄링 기법
- Zigbee : 홈 네트워크 및 무선 센서망에서 사용되는 기술로, 버튼 하나의 동작으로 집안 어느 곳에서나 전등 제어 및 홈 보안 시스템을 제어관리하는 가정 자동화를 목표로 출발하였음.
- 단일 책임원칙 : 하나의 객체는 하나의 동작만의 책임을 가짐
- 개방-폐쇄의 원칙 : 클래스는 확장에 대해 열려 있어야 하 며 변경에 대해 닫혀 있어야 한다.
- 리스코프 교체의 원칙 : 특정 메소드가 상위 타입을 인자 로 사용할 때, 그 타입의 하위 타입도 문제 없이 작동해야 함
- 의존관계 역전의 원칙 : 상위 계층이 하위 계층에 의존하 는 전통적인 의존관계를 반전(역전)시킴으로써 상위 계층이 하위 계층의 구현으로부터 독립되게 할 수 있음

- EAI(Enterprise Application Integration): 기업 응용 프로그램 통합으로 기업용 응용 프로그램의 구조적 통합 방안을 가리킴
- FEP(Front-End Processor): 입력되는 데이터를 컴퓨터의 프 로세서가 처리하기 전에 미리 처리하여 프로세서가 차지하는 시간을 줄여주는 프로그램이나 하드웨어
- GPL(General Public License): 자유 소프트웨어 재단(OSF)에 서 만든 자유 소프트웨어 라이선스
- Duplexing: 이중화(데이터베이스의 회복 기법 중 가장 간단한 것)
- AJTML(Asynchronous Javascript and XML) : AJAX 기술을 사용하여 서버와 비동기적으로 데이터를 주고받기 위한 표준이다.
- JSON(Javascript Object Notation) : 경량화된 데이터 교환 형식으로, JavaScript에서 객체를 표현하는 방법을 사용한다.
- XML(Extensible Markup Language) : 다목적 마크업 언어로, 데이터를 저장하고 전송하기 위한 공통적인 형식이다.GPL(General Public License): 자유 소프트웨어 재단(OSF)에 서 만든 자유 소프트웨어 라이선스
- YAML(YAML Ain't Markup Language): 인간이 쉽게 읽을 수 있는 데이터 직렬화 언어로, 데이터의 가독성을 높이고, 데이터 간의 관계를 쉽게 파악한다.
AJTML은 서버와 클라이언트 간의 통신을 위해 이용되는 데이터 포맷이다.

printf("%d, ", *(p[0]+1) + *(p[1]+2)); → p[0]은 arr[0]을 가리키고, p[0] + 1은 arr[0][1] 즉, 값 2를 가리킵니다. p[1]은 arr[1]을 가리키고, p[1] + 2는 arr[1][2] 즉, 값 6을 가리킵니다. 따라서, *(p[0]+1) + *(p[1]+2)의 값은 2 + 6 = 8이 됩니다.
printf("%d", *(*(p+1)+0) + *(*(p+1)+1)); → p+1은 arr[1]을 가리킵니다. *(p+1)+0은 arr[1][0] 즉, 값 4를 가리킵니다. *(p+1)+1은 arr[1][1] 즉, 값 5를 가리킵니다. 따라서, *(*(p+1)+0) + *(*(p+1)+1)의 값은 4 + 5 = 9이 됩니다.
따라서 최종 출력은 8, 9 입니다.
- IP : 경로 설정 기능. 비연결형인 데이터그램 방식 → 신뢰성 보장X
- ICMP : 통신 중 발생하는 오류 처리를 위한 제어 메시지 관리
- IGMP : 멀티캐스트 그룹 유지
- ARP : IP → MAC 주소
- RARP : MAC → IP 주소
- ARP : IP 네트워크 상에서 IP주소를 MAC주소로 변환하는 프로토콜
- ICMP : IP와 조합하여 통신 중에 발생하는 오류의 처리와 전 송 경로 변경 등을 위한 제어 메시지를 관리하는 역할을 하는 프로토콜
- PPP : 점대점 데이터링크를 통해 3계층 프로토콜들을 캡슐화 시켜 전송하는 프로토콜
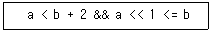
a < b + 2 : 여기서 b + 2는 4입니다. 따라서 조건은 1 < 4로 참입니다.
a << 1 <= b : 먼저 a << 1은 a를 왼쪽으로 1비트 이동시킨 값이므로, 10을 100으로 만들어 2를 나타냅니다. 그 후, 2 <= b는 2 <= 2로 참입니다.
따라서 전체 조건식은 참이 됩니다.

- 고가용성 솔루션(HACMP:High Availability Cluster Multi Processing)
- >AIX를 기반으로 한 IBM의 High Availability Solution
- Resource의 중복 또는 공유를 통해 Application의 보호를 가능하게 해줌
- 같은 Data를 공유하거나 동시에 access하는 node들에서 여러 개의 application을 실행하게 해줌
- 두대 이상의 시스템을 하나의 Cluster로 묶어 Cluster내의 한 시스템에서 장애가 발생할 경우 다른 시스템이 장애가 발 생한 시스템의 자원을 인수할 수 있도록 하여 서비스의 중단 을 최소화 할 수 있도록 도와주는 솔루션
- 점대점 연결 방식(Point-to-Point Mode)
- 네트워크에 있어 물리적으로는 중개 장치를 통과하지 않고 한 지점에서 다른 지점으로 직접 가는 채널
- 두 스테이션간을 별도의 회선을 사용하여 1 대 1로 연결 → 전용회선이나 공중 전화 회선을 이용
- 회선 구성이 간단하고 대용량 전송에 유리
- 별도의 회선과 포트에 따른 높은 설치비용
- 스턱스넷(Stuxnet)
- 2010년 6월에 발견된 웜 바이러스
- 윈도우를 통해 감염, 지맨스산업의 SW 및 장비를 공격
- 루팅(Rooting)
- 모바일 기기에서 구동되는 안드로이드 운영체제상에서 최상위 권한 (루트 권한)을 얻음으로 해당 기기의 생산자 또는 판매자 측에서 걸어 놓은 제약을 해제하는 행위

- StackGuard : Stack 상에 일정한 주소번지에 프로그램이 선언한 canary를 심어두어, 스택의 변조된 경우에, canary를 체크하여 프로그램을 비정상적으로 종료시키는 기법
- Docker
- 컨테이너 응용프로그램의 배포를 자동화 하는 오픈소스 엔진
- SW 컨터에이너 안의 응용 프로그램들을 배치시키는 일을 자동화해주는 오픈소스 프로젝트이자 소프트웨어
- Cipher Container : 자바에서 암호화 복호화 기능을 제공하는 컨테이너
- Scytale : 암호화 기법으로 단순하게 문자열의 위치를 바꾸는 방법
DES의 비트수는 64비트이다. 7비트마다 오류 검출을 위한 정보가 1비트씩 들어가기 때문에 실질적으로는 56비트이다.
AES는 암호화 알고리즘은 비트수에 따라 AES-128, AES-192, AES-256로 나뉜다.
- 디렉토리 : 777 - umask
- 파일 : 666 - umask
666 - 644 = 022

- PERT(Program Evaluation and Review Technique, 프로그램 평가 및 검토 기술) : 노드와 간선으로 구성(낙관치, 기대치, 비관치 표시), 결정 경로, 작업에 대한 경계 시간, 작업 간의 상호관련성 등을 알 수 있다.
- 간트차트 : 작업 일정을 막대 도표를 이용(시간선 차트), 이정표, 작업일정, 작업기간, 산출물로 구성된다. 수평 막대의 길이는 각 작업의 기간이다.